dissecting linux schedulers & implementing our toy cfs_scheduler simulation
Abstract
Linux scheduling involves multiple things like which tasks to pick, how to pick, how to maximize the CPU utilisation etc. Over the time scheduling algorithms evolved from FIFO, RR to EDF and CFS. These algorithms performs better in different type of tasks i.e. real time, hard limit tasks. An algorithm that is better in scheduling real time tasks is not necessary that it will be able to schedule a hard limit task. This article is the study of what Scheduling heuristics are there to take in mind before checking any scheduling algorithm, how different schedulers evolved and how they are being in use. At the end we will run some simulations with different kind of tasks in our toy cfs schedular simulation.
TL;DR
- Linux schedulars evolved over time from FIFO, RR to O(1) and CFS
- Each schedular behave differently for different type of tasks
- We would explore evolution of schedulars, checking schedulable tasks
- We will see Dahll's effect, Uniprocessors and Multiprocessors behaviour
- We simulated a set of tasks in our toy cfs_schedular
1.1 Task scheduling
Whenever we have a set of tasks and to check if this set is schedulable, we need to check if it exceeds CPU utilisation or not.
where
is the cpu time that will take to complete its exection
is the time interval after which 's second instance will be released
is the deadline before which that should complete its execution
Note:- is a common assumption for real time systems
1.1.1 For Uniprocessor:-
For uniprocessors or single processors there should exsist a function which maps to a set of tasks containing runnable and idle tasks
- If , it means that at time t, a specific task is being executed
- If , it means the system is idle at time t which mean no task is being run
1.1.2 For Multiprocessor:-
Let say we have multiprocessors setup with CPUs. For multiprocessor should map a matrix of tasks to CPUs to time as:-
:
Note:- Hence, is a scheduling function in the context of CPU scheduling which determines which task is assigned to execution at any given time t
In dual core processor for at time will look like:-
For there is two types of scheduling that we will look at:- Global scheduling, Partitioned Scheduling
1.2 Schedulable Task Set
For N periodic tasks, the task set is schedulable if
which essentially means that summing up all the utilisation of CPU per task is still not maxium which is 100% of CPU capacity.
similarly, for multiprocessor this equation becomes
which essentially means that summing up all the capacity used by the task set it should not exceed the total CPU capacity available.
1.2.1 Dhall's Effect
Even if we have then also it is possible that task is not schedulable because of its high utilisation behaviour that is also called hard limit task.
Let's take an example of tasks where and then CPU utilisation upper bound can be found as:-
Now, as which is possible for real time tasks then
In this case EDF (earliest deadline first) and RM (rate monotonic) scheduling algorithm can not be used because they are not meant for hard tasks.
Hence, even if utilisation is less than what we want but it doesn't guarantee if task set is schedulable. Therefore, algorithms like EDF and RM are applicable only for soft tasks.
1.3 Constant Bandwidth Server (CBS)
Constant bandwidth server is used for hard limit tasks where it ensures that tasks meet their deadlines by allocating a constant bandwidth allocation to them.
It allocates capacity that a task can use and periodic interval after which task's instance can run. . In other words task is allocated a maximum runtime of after every periodic interval of
If task wants to run for more than allcated every then algorithm throttles/decreases its priority.
where is guranteed to receive every interval.
Each task's dynamic deadline is maintained and throttled according to the history and allocated bandwidth. For cpus/cores with global scheduling if then CBS guarantees the scheduling of tasks from a task set.
1.3.1 CBS Algorithm - 1
Each task starts with a dynamic deadline that are initialised as 0 when task is created.
When task wakes up, check if current deadline can be used:-
and
If not, and
This ensures that when a task wakes up, it will get its share of cpu after the alloted wait time. But if task wants to run for more time than allocated then its priority will be throttled.
CBS algorithm is generally used in RTOS (real time OS) or real time tasks where they have to meet the deadline or the deadline is critical.
1.4 Complete Fair Schedular (CFS)
CFS is an algorithm which can be used in general to schedule the tasks instead of CBS which is favorable for real time tasks. CFS relies on the hypothesis that it can give a fair share to each task in a task set.
CFS uses few terms/parameters as stated below:-
- weight:- a priority or niceness in UNIX systems that is given to each task
- timeslice:- an interval given to each task which tells that in this time task has to run atleast once
- vruntime:- runtime divided by thread's weight that essentially means that high priority thread will have less vruntime
High priority task's rate of increase of vruntime is slower compared to lower priority (less weight) task - runqueue:- CFS relies on runqueues which are nothing but red-black tree with ascending vruntime. CFS picks lower most task when scheduling a new task. Which means high priority task will be executed more as compared to low priority task
1.4.1 Our toy CFS simulation
We made a simulation where our cfs picks up the tasks from a runnable queue (priority min queue according to vruntime). At every task has some vruntime, some random values are given instead of zeros, and vruntime increases like:-
- at push all tasks into the runnable queue having both CPU and IO tasks
- have one vruntime calculation function which calculate task vruntime according to the task's priority:-
- which means higher the task's priority (lower value of priority variable) will give higher the value of weight
- heigher the value of weight lower rate of increase in vruntime of that task
CFS simluation
GLOABAL NICE_0_LOAD = 1024
FUNCTION weight_function(priority):
return NICE_0_LOAD / (priorit + 1)
FUNCTION run_io_bound(process, iowait, queue):
sleep_thread(iowait)
weight = weight_function(process.priority)
process.vruntime += (iowait * NICE_0_LOAD) / weight
executed_time = 1
process.cpu_burst_time -= executed_time
process.vruntime += (executed_time * NICE_0_LOAD) / weight
if process.cpu_burst_time > 0:
queue.push(process)
FUNCTION run_cpu_bound(process, timeslice, queue):
executed_time = min(timeslice, process.cpu_burst_time)
process.cpu_burst_time -= executed_time
weight = weight_function(process.priority)
process.vruntime += (executed_time * NICE_0_LOAD) / weight
if process.cpu_burst_time > 0:
queue.push(process)
LOOP task in queue:
if task is cpu_bound:
run_cpu_task(task, 1, queue)
else
run_io_task(task, 10, queue)
1.4.2 Some simulations:-
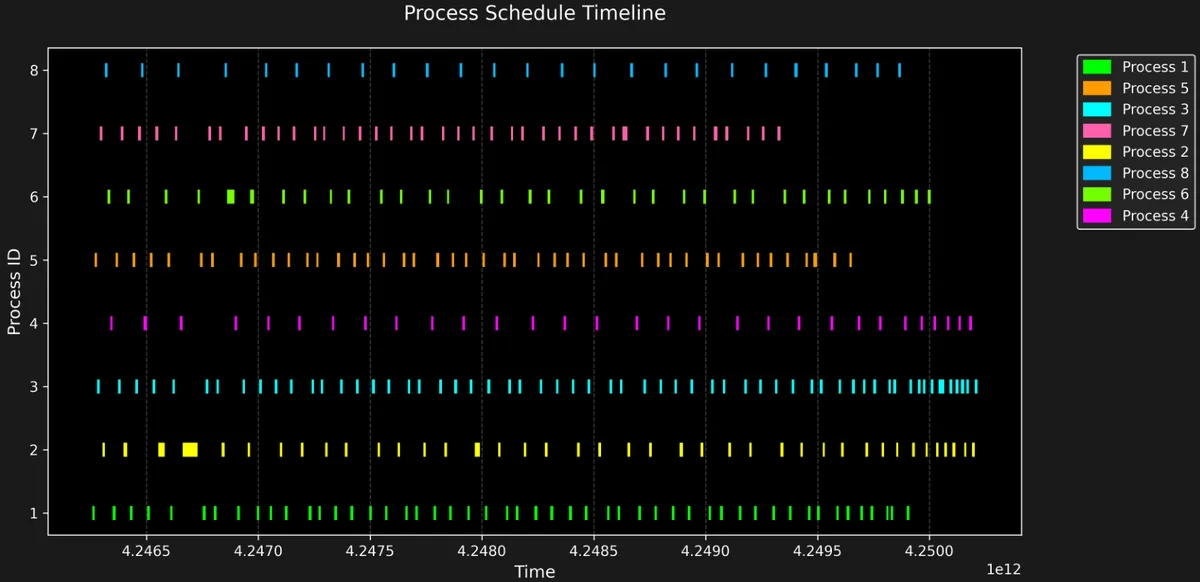
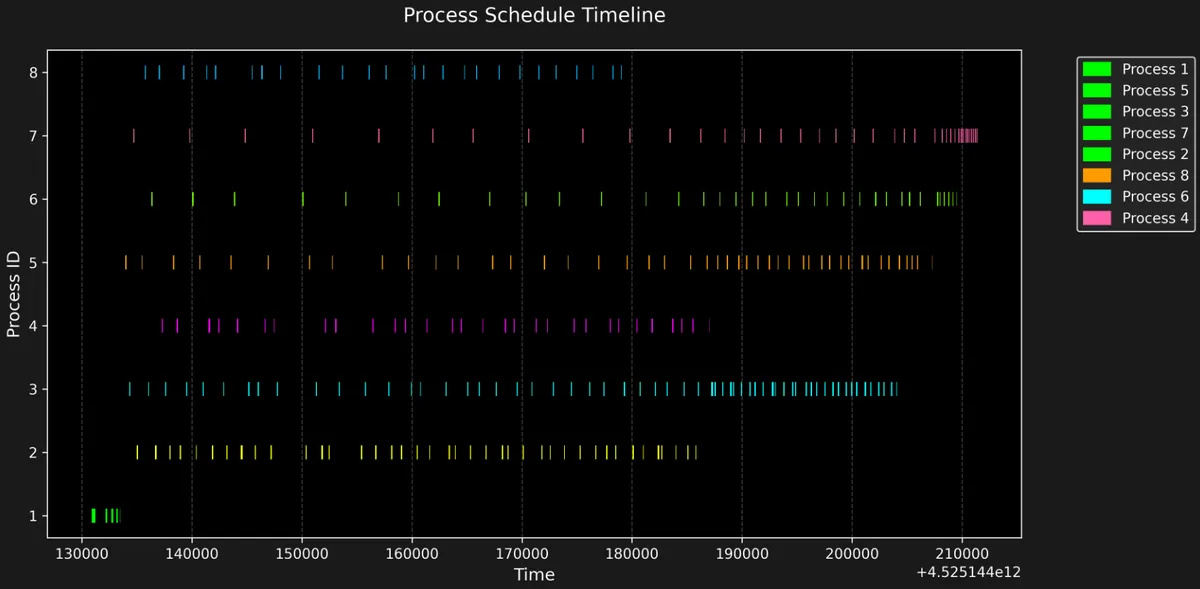
First simulation is of processes with different vruntime, priority etc but all processes are of IO_BOUND nature whereas second one contains all CPU_BOUND processes.
We can clearly see that IO tasks are waiting for their iowait time and getting penalised. More priority IO task is getting more penalised and scheduling will get delayed whereas in CPU bound tasks, Process 1 got finalised quickly because it has the highest priroirty and got penalised the least because it started with least vruntime and highest priority. So, resulted in more frequent scheduling.